«∞—‘
ZooKeeper «“ª∏ˆø™‘¥µƒ∑÷≤º Ω–≠µ˜∑˛ŒÒ£¨”…—≈ª¢¥¥Ω®£¨ « Google Chubby µƒø™‘¥ µœ÷°£∑÷≤º Ω”¶”√≥ÖÚø…“‘ª˘”⁄ ZooKeeper µœ÷÷Ó»Á ˝æ›∑¢≤º/∂©‘ƒ°¢∏∫‘ÿæ˘∫‚°¢√¸√˚∑˛ŒÒ°¢∑÷≤º Ω–≠µ˜/Õ®÷™°¢ºØ»∫π‹¿Ì°¢Master —°æŸ°¢∑÷≤º ΩÀ¯∫Õ∑÷≤º Ω∂”¡–µ»π¶ƒ‹°£
1°¢ºÚΩÈ
ZooKeeper «“ª∏ˆø™‘¥µƒ∑÷≤º Ω–≠µ˜∑˛ŒÒ£¨”…—≈ª¢¥¥Ω®£¨ « Google Chubby µƒø™‘¥ µœ÷°£∑÷≤º Ω”¶”√≥ÖÚø…“‘ª˘”⁄ ZooKeeper µœ÷÷Ó»Á ˝æ›∑¢≤º/∂©‘ƒ°¢∏∫‘ÿæ˘∫‚°¢√¸√˚∑˛ŒÒ°¢∑÷≤º Ω–≠µ˜/Õ®÷™°¢ºØ»∫π‹¿Ì°¢Master —°æŸ°¢∑÷≤º ΩÀ¯∫Õ∑÷≤º Ω∂”¡–µ»π¶ƒ‹°£
2°¢ª˘±æ∏≈ƒÓ
±æΩ⁄Ω´ΩÈ…‹ ZooKeeper µƒº∏∏ˆ∫À–ƒ∏≈ƒÓ°£’‚–©∏≈ƒÓ𷥩”⁄÷Æ∫Û∂‘ ZooKeeper ∏¸…ӻεƒΩ≤Ω‚£¨“Ú¥À”–±ÿ“™‘§œ»¡ÀΩ‚’‚–©∏≈ƒÓ°£
2.1 ºØ»∫Ω«…´
‘⁄ ZooKeeper ÷–£¨”–»˝÷÷Ω«…´£∫
Leader
Follower
Observer
“ª∏ˆ ZooKeeper ºØ»∫Õ¨“ª ±øÃ÷ªª·”–“ª∏ˆ Leader£¨∆‰À˚∂º « Follower ªÚ Observer°£
ZooKeeper ≈‰÷√∫‹ºÚµ•£¨√ø∏ˆΩ⁄µ„µƒ≈‰÷√Œƒº˛(zoo.cfg)∂º «“ª—˘µƒ£¨÷ª”– myid Œƒº˛≤ª“ª—˘°£myid µƒ÷µ±ÿ–Î « zoo.cfg÷–server.{ ˝÷µ} µƒ{ ˝÷µ}≤ø∑÷°£
zoo.cfg Œƒº˛ƒ⁄»› æ¿˝£∫
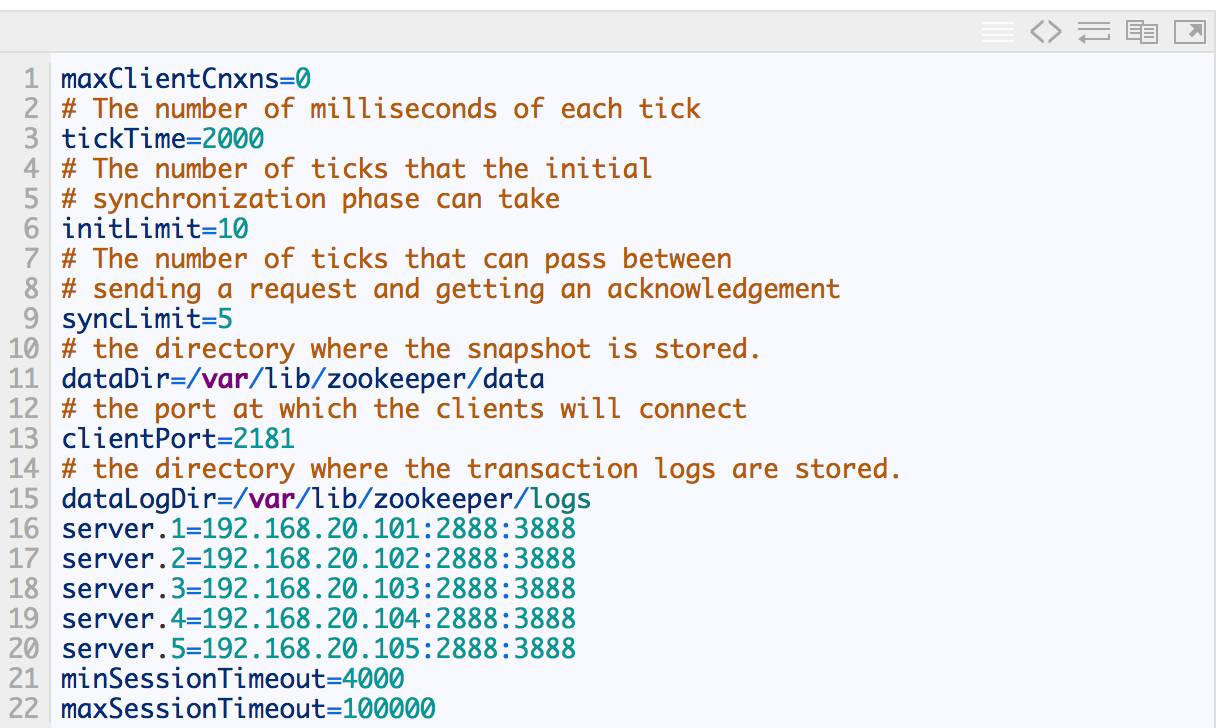
‘⁄◊∞”– ZooKeeper µƒª˙∆˜µƒ÷’∂À÷¥–– zookeeper-server status ø…“‘ø¥µ±«∞Ω⁄µ„µƒ ZooKeeper « ≤√¥Ω«…´£®Leader or Follower£©°£
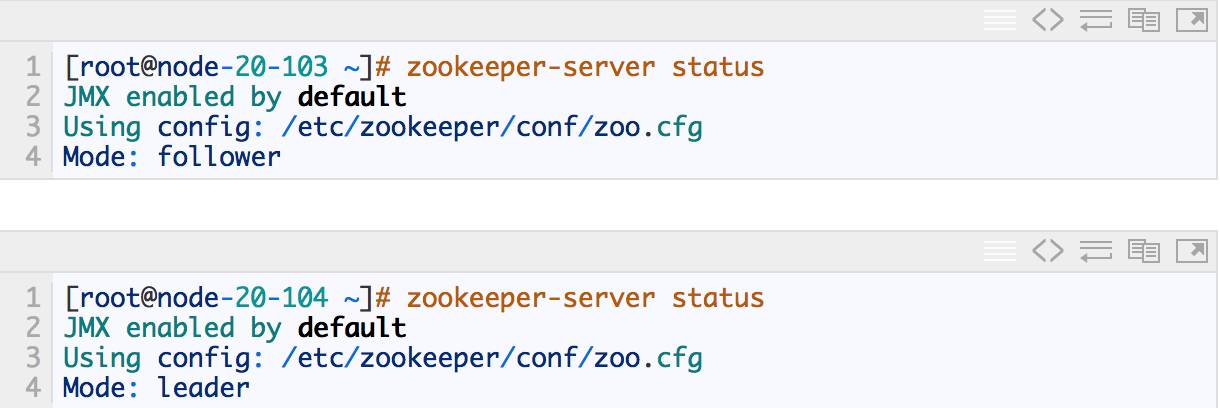
»Á…œ£¨node-20-104 « Leader£¨node-20-103 « follower°£
ZooKeeper ƒ¨»œ÷ª”– Leader ∫Õ Follower ¡Ω÷÷Ω«…´£¨√ª”– Observer Ω«…´°£Œ™¡À π”√ Observer ƒ£ Ω£¨‘⁄»Œ∫ŒœÎ±‰≥…ObserverµƒΩ⁄µ„µƒ≈‰÷√Œƒº˛÷–º”»Î:peerType=observer ≤¢‘⁄À˘”– server µƒ≈‰÷√Œƒº˛÷–£¨≈‰÷√≥… observer ƒ£ Ωµƒ server µƒƒ«––≈‰÷√◊∑º” :observer£¨¿˝»Á£∫
server.1:localhost:2888:3888:observer
ZooKeeper ºØ»∫µƒÀ˘”–ª˙∆˜Õ®π˝“ª∏ˆ Leader —°æŸπ˝≥ÿ¥—°∂®“ªÃ®±ª≥∆Œ™°∫Leader°ªµƒª˙∆˜£¨Leader∑˛ŒÒ∆˜Œ™øÕªß∂À÷π©∂¡∫Õ–¥∑˛ŒÒ°£
Follower ∫Õ Observer ∂ºƒ‹Ã·π©∂¡∑˛ŒÒ£¨≤ªƒ‹Ã·π©–¥∑˛ŒÒ°£¡Ω’flŒ®“ªµƒ«¯±‘⁄”⁄£¨Observer ª˙∆˜≤ª≤Œ”Î Leader —°æŸπ˝≥㨓≤≤ª≤Œ”Ζ¥≤Ÿ◊˜µƒ°∫π˝∞Ζ¥≥…π¶°ª≤fl¬‘£¨“Ú¥À Observer ø…“‘‘⁄≤ª”∞œÏ–¥–‘ƒ‹µƒ«Èøˆœ¬Ã·…˝ºØ»∫µƒ∂¡–‘ƒ‹°£
2.2 ª·ª∞£®Session£©
Session «÷∏øÕªß∂Àª·ª∞£¨‘⁄Ω≤Ω‚øÕªß∂Àª·ª∞÷Æ«∞£¨Œ“√«œ»¿¥¡ÀΩ‚œ¬øÕªß∂À¡¨Ω”°£‘⁄ ZooKeeper ÷–£¨“ª∏ˆøÕªß∂À¡¨Ω” «÷∏øÕªß∂À∫Õ ZooKeeper ∑˛ŒÒ∆˜÷ƺ‰µƒTCP≥§¡¨Ω”°£
ZooKeeper ∂‘Õ‚µƒ∑˛ŒÒ∂Àø⁄ƒ¨»œ «2181£¨øÕªß∂À∆Ù∂Ø ±£¨ ◊œ»ª·”Î∑˛ŒÒ∆˜Ω®¡¢“ª∏ˆTCP¡¨Ω”£¨¥”µ⁄“ª¥Œ¡¨Ω”Ω®¡¢ø™ º£¨øÕªß∂Àª·ª∞µƒ…˙√¸÷‹∆⁄“≤ø™ º¡À£¨Õ®π˝’‚∏ˆ¡¨Ω”£¨øÕªß∂Àƒ‹πªÕ®π˝–ƒÃ¯ºÏ≤‚∫Õ∑˛ŒÒ∆˜±£≥÷”––ßµƒª·ª∞£¨“≤ƒ‹πªœÚ ZooKeeper ∑˛ŒÒ∆˜∑¢ÀիΫÛ≤¢Ω” ‹œÏ”¶£¨Õ¨ ±ªπƒ‹Õ®π˝∏√¡¨Ω”Ω” ’¿¥◊‘∑˛ŒÒ∆˜µƒ Watch ¬º˛Õ®÷™°£
Session µƒ SessionTimeout ÷µ”√¿¥…Ë÷√“ª∏ˆøÕªß∂Àª·ª∞µƒ≥¨ ± ±º‰°£µ±”…”⁄∑˛ŒÒ∆˜—π¡¶Ã´¥Û°¢Õ¯¬Áπ ’œªÚ «øÕªß∂À÷˜∂Ø∂œø™¡¨Ω”µ»∏˜÷÷‘≠“Úµº÷¬øÕªß∂À¡¨Ω”∂œø™ ±£¨÷ª“™‘⁄ SessionTimeout πÊ∂®µƒ ±º‰ƒ⁄ƒ‹πª÷ÿ–¬¡¨Ω”…œºØ»∫÷–»Œ“‚“ªÃ®∑˛ŒÒ∆˜£¨ƒ«√¥÷Æ«∞¥¥Ω®µƒª·ª∞»‘»ª”––ß°£
2.3 ˝æ›Ω⁄µ„£®ZNode£©
‘⁄Ã∏µΩ∑÷≤º Ωµƒ ±∫Ú£¨“ª∞„°∫Ω⁄µ„°ª÷∏µƒ «◊È≥…ºØ»∫µƒ√ø“ªÃ®ª˙∆˜°£∂¯ZooKeeper ÷–µƒ ˝æ›Ω⁄µ„ «÷∏ ˝æ›ƒ£–Õ÷–µƒ ˝æ›µ•‘™£¨≥∆Œ™ ZNode°£ZooKeeper Ω´À˘”– ˝æ›¥Ê¥¢‘⁄ƒ⁄¥Ê÷–£¨ ˝æ›ƒ£–Õ «“ªø√ ˜£®ZNode Tree£©£¨”…–±∏‹£®/£©Ω¯––∑÷∏Óµƒ¬∑æ∂£¨æÕ «“ª∏ˆZNode£¨»Á /hbase/master£¨∆‰÷– hbase ∫Õ master ∂º « ZNode°£√ø∏ˆ ZNode …œ∂ºª·±£¥Ê◊‘º∫µƒ ˝æ›ƒ⁄»›£¨Õ¨ ±ª·±£¥Ê“ªœµ¡– Ù–‘–≈œ¢°£
◊¢£∫
’‚¿Ôµƒ ZNode ø…“‘¿ÌΩ‚≥…º» «Unix¿ÔµƒŒƒº˛£¨”÷ «Unix¿Ôµƒƒø¬º°£“ÚŒ™√ø∏ˆ ZNode ≤ªΩˆ±æ…Ìø…“‘–¥ ˝æ›£®œ‡µ±”⁄Unix¿ÔµƒŒƒº˛£©£¨ªπø…“‘”–œ¬“ªº∂Œƒº˛ªÚƒø¬º£®œ‡µ±”⁄Unix¿Ôµƒƒø¬º£©°£
‘⁄ ZooKeeper ÷–£¨ZNode ø…“‘∑÷Œ™≥÷æ√Ω⁄µ„∫Õ¡Ÿ ±Ω⁄µ„¡Ω¿‡°£
≥÷æ√Ω⁄µ„
À˘ŒΩ≥÷æ√Ω⁄µ„ «÷∏“ªµ©’‚∏ˆ ZNode ±ª¥¥Ω®¡À£¨≥˝∑«÷˜∂ØΩ¯–– ZNode µƒ“∆≥˝≤Ÿ◊˜£¨∑Ò‘Ú’‚∏ˆ ZNode Ω´“ª÷±±£¥Ê‘⁄ ZooKeeper …œ°£
¡Ÿ ±Ω⁄µ„
¡Ÿ ±Ω⁄µ„µƒ…˙√¸÷‹∆⁄∏˙øÕªß∂Àª·ª∞∞Û∂®£¨“ªµ©øÕªß∂Àª·ª∞ ߖߣ¨ƒ«√¥’‚∏ˆøÕªß∂À¥¥Ω®µƒÀ˘”–¡Ÿ ±Ω⁄µ„∂ºª·±ª“∆≥˝°£
¡ÌÕ‚£¨ZooKeeper ªπ‘ –Ì”√ªßŒ™√ø∏ˆΩ⁄µ„Ã̺”“ª∏ˆÃÿ ‚µƒ Ù–‘£∫SEQUENTIAL°£“ªµ©Ω⁄µ„±ª±Íº«…œ’‚∏ˆ Ù–‘£¨ƒ«√¥‘⁄’‚∏ˆΩ⁄µ„±ª¥¥Ω®µƒ ±∫Ú£¨ZooKeeper æÕª·◊‘∂Ø‘⁄∆‰Ω⁄µ„∫Û√Ê◊∑º”…œ“ª∏ˆ’˚–Õ ˝◊÷£¨’‚∏ˆ’˚–Õ ˝◊÷ «“ª∏ˆ”…∏∏Ω⁄µ„Œ¨ª§µƒ◊‘‘ˆ ˝◊÷°£
2.4 ∞ʱæ
ZooKeeper µƒ√ø∏ˆ ZNode …œ∂ºª·¥Ê¥¢ ˝æ›£¨∂‘”¶”⁄√ø∏ˆ ZNode£¨ZooKeeper ∂ºª·Œ™∆‰Œ¨ª§“ª∏ˆΩ–◊˜ Stat µƒ ˝æ›Ω·ππ£¨Stat ÷–º«¬º¡À’‚∏ˆ ZNode µƒ»˝∏ˆ ˝æ›∞ʱ棨∑÷± « version£®µ±«∞ZNodeµƒ∞ʱ棩°¢cversion£®µ±«∞ZNode◊”Ω⁄µ„µƒ∞ʱ棩∫Õ aversion£®µ±«∞ ZNode µƒ ACL ∞ʱ棩°£
2.5 ◊¥Ã¨–≈œ¢
√ø∏ˆ ZNode ≥˝¡À¥Ê¥¢ ˝æ›ƒ⁄»›÷ÆÕ‚£¨ªπ¥Ê¥¢¡À ZNode ±æ…̵ƒ“ª–©◊¥Ã¨–≈œ¢°£”√ get √¸¡Óø…“‘Õ¨ ±ªÒµ√ƒ≥∏ˆ ZNode µƒƒ⁄»›∫Õ◊¥Ã¨–≈œ¢°£»Áœ¬£∫
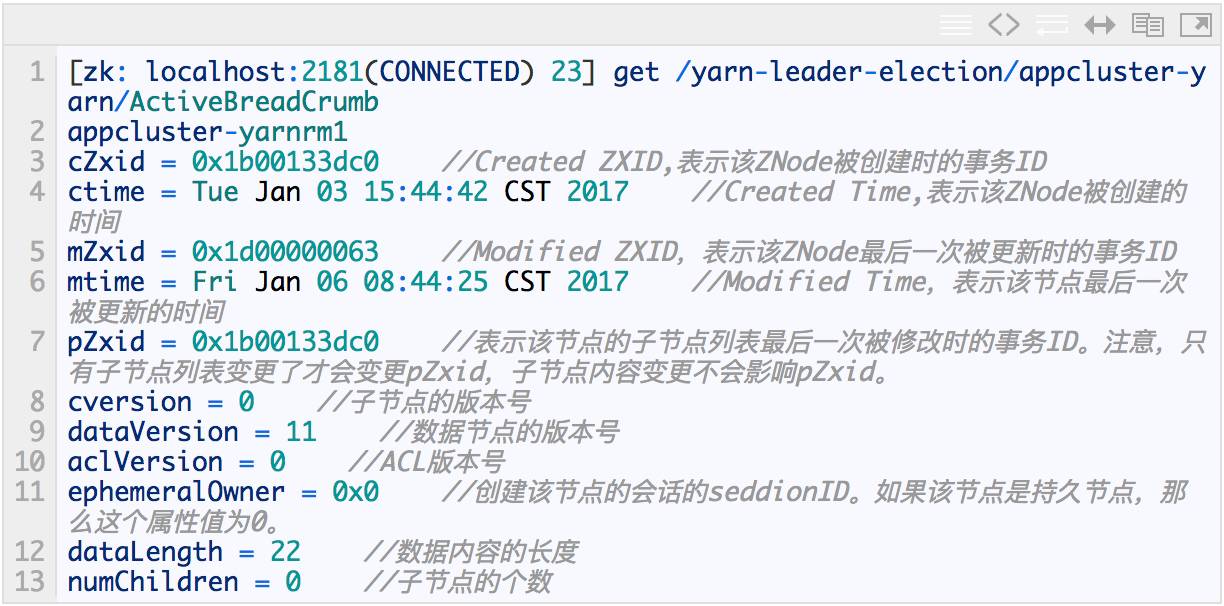
‘⁄ ZooKeeper ÷–£¨version Ù–‘ «”√¿¥ µœ÷¿÷π€À¯ª˙÷∆÷–µƒ°∫–¥»Î–£—È°ªµƒ£®±£÷§∑÷≤º Ω ˝æ›‘≠◊”–‘≤Ÿ◊˜£©°£
2.6 ¬ŒÒ≤Ÿ◊˜
‘⁄ZooKeeper÷–£¨ƒ‹∏ƒ±‰ZooKeeper∑˛ŒÒ∆˜◊¥Ã¨µƒ≤Ÿ◊˜≥∆Œ™ ¬ŒÒ≤Ÿ◊˜°£“ª∞„∞¸¿® ˝æ›Ω⁄µ„¥¥Ω®”Î…æ≥˝°¢ ˝æ›ƒ⁄»›∏¸–¬∫ÕøÕªß∂Àª·ª∞¥¥Ω®”Î ß–ßµ»≤Ÿ◊˜°£∂‘”¶√ø“ª∏ˆ ¬ŒÒ«Î«Û£¨ZooKeeper ∂ºª·Œ™∆‰∑÷≈‰“ª∏ˆ»´æ÷Œ®“ªµƒ ¬ŒÒID£¨”√ ZXID ±Ì 棨ծ≥£ «“ª∏ˆ64Œªµƒ ˝◊÷°£√ø“ª∏ˆ ZXID ∂‘”¶“ª¥Œ∏¸–¬≤Ÿ◊˜£¨¥”’‚–© ZXID ÷–ø…“‘º‰Ω”µÿ ∂±≥ˆ ZooKeeper ¥¶¿Ì’‚–© ¬ŒÒ≤Ÿ◊˜«Î«Ûµƒ»´æ÷À≥–Ú°£
2.7 Watcher
Watcher£® ¬º˛º‡Ã˝∆˜£©£¨ « ZooKeeper ÷–“ª∏ˆ∫‹÷ÿ“™µƒÃÿ–‘°£ZooKeeper‘ –Ì”√ªß‘⁄÷∏∂®Ω⁄µ„…œ◊¢≤·“ª–© Watcher£¨≤¢«“‘⁄“ª–©Ãÿ∂® ¬º˛¥•∑¢µƒ ±∫Ú£¨ZooKeeper ∑˛ŒÒ∂Àª·Ω´ ¬º˛Õ®÷™µΩ∏––À»§µƒøÕªß∂À…œ»•°£∏√ª˙÷∆ « ZooKeeper µœ÷∑÷≤º Ω–≠µ˜∑˛ŒÒµƒ÷ÿ“™Ãÿ–‘°£
2.8 ACL
ZooKeeper ≤…”√ ACL£®Access Control Lists£©≤fl¬‘¿¥Ω¯––»®œfiøÿ÷∆°£ZooKeeper ∂®“¡À»Áœ¬5÷÷»®œfi°£
CREATE: ¥¥Ω®◊”Ω⁄µ„µƒ»®œfi°£
READ: ªÒ»°Ω⁄µ„ ˝æ›∫Õ◊”Ω⁄µ„¡–±Ìµƒ»®œfi°£
WRITE£∫∏¸–¬Ω⁄µ„ ˝æ›µƒ»®œfi°£
DELETE: …æ≥˝◊”Ω⁄µ„µƒ»®œfi°£
ADMIN: …Ë÷√Ω⁄µ„ACLµƒ»®œfi°£
◊¢“‚£∫CREATE ∫Õ DELETE ∂º «’Î∂‘◊”Ω⁄µ„µƒ»®œfiøÿ÷∆°£
3. ZooKeeperµ‰–Õ”¶”√≥°æ∞
ZooKeeper «“ª∏ˆ∏flø…”√µƒ∑÷≤º Ω ˝æ›π‹¿Ì”Ζ≠µ˜øÚº‹°£ª˘”⁄∂‘ZABÀ„∑®µƒ µœ÷£¨∏√øÚº‹ƒ‹πª∫‹∫√µÿ±£÷§∑÷≤º Ωª∑æ≥÷– ˝æ›µƒ“ª÷¬–‘°£“≤ «ª˘”⁄’‚—˘µƒÃÿ–‘£¨ πµ√ ZooKeeper ≥…Œ™¡ÀΩ‚æˆ∑÷≤º Ω“ª÷¬–‘Œ µƒ¿˚∆˜°£
3.1 ˝æ›∑¢≤º”Î∂©‘ƒ£®≈‰÷√÷––ƒ£©
˝æ›∑¢≤º”Î∂©‘ƒ£¨º¥À˘ŒΩµƒ≈‰÷√÷––ƒ£¨πÀ√˚Àº“ÂæÕ «∑¢≤º’flΩ´ ˝æ›∑¢≤ºµΩ ZooKeeper Ω⁄µ„…œ£¨π©∂©‘ƒ’flΩ¯–– ˝æ›∂©‘ƒ£¨Ω¯∂¯¥ÔµΩ∂ØèªÒ»° ˝æ›µƒƒøµƒ£¨ µœ÷≈‰÷√–≈œ¢µƒºØ÷– Ωπ‹¿Ì∫Õ∂Øè∏¸–¬°£
‘⁄Œ“√«∆Ω≥£µƒ”¶”√œµÕ≥ø™∑¢÷–£¨æ≠≥£ª·≈ˆµΩ’‚—˘µƒ–Ë«Û£∫œµÕ≥÷––Ë“™ π”√“ª–©Õ®”√µƒ≈‰÷√–≈œ¢£¨¿˝»Áª˙∆˜¡–±Ì–≈œ¢°¢ ˝æ›ø‚≈‰÷√–≈œ¢µ»°£’‚–©»´æ÷≈‰÷√–≈œ¢Õ®≥£æfl±∏“‘œ¬3∏ˆÃÿ–‘°£
˝æ›¡øÕ®≥£±»Ωœ–°°£
˝æ›ƒ⁄»›‘⁄‘À–– ±∂Ø豉ªØ°£
ºØ»∫÷–∏˜ª˙∆˜π≤œÌ£¨≈‰÷√“ª÷¬°£
∂‘”⁄’‚—˘µƒ»´æ÷≈‰÷√–≈œ¢æÕø…“‘∑¢≤ºµΩ ZooKeeper…œ£¨»√øÕªß∂À£®ºØ»∫µƒª˙∆˜£©»•∂©‘ƒ∏√œ˚œ¢°£
∑¢≤º/∂©‘ƒœµÕ≥“ª∞„”–¡Ω÷÷…˺∆ƒ£ Ω£¨∑÷± «Õ∆£®Push£©∫Õ¿≠£®Pull£©ƒ£ Ω°£
Õ∆£∫∑˛ŒÒ∂À÷˜∂ØΩ´ ˝æ›∏¸–¬∑¢ÀÕ∏¯À˘”–∂©‘ƒµƒøÕªß∂À°£
¿≠£∫øÕªß∂À÷˜∂Ø∑¢∆«Î«Û¿¥ªÒ»°◊Ó–¬ ˝æ›£¨Õ®≥£øÕªß∂À∂º≤…”√∂® ±¬÷—Ø¿≠»°µƒ∑Ω Ω°£
ZooKeeper ≤…”√µƒ «Õ∆¿≠œ‡Ω·∫œµƒ∑Ω Ω°£»Áœ¬£∫
øÕªß∂ÀœÎ∑˛ŒÒ∂À◊¢≤·◊‘º∫–Ë“™πÿ◊¢µƒΩ⁄µ„£¨“ªµ©∏√Ω⁄µ„µƒ ˝æ›∑¢…˙±‰∏¸£¨ƒ«√¥∑˛ŒÒ∂ÀæÕª·œÚœ‡”¶µƒøÕªß∂À∑¢ÀÕWatcher ¬º˛Õ®÷™£¨øÕªß∂ÀΩ” ’µΩ’‚∏ˆœ˚œ¢Õ®÷™∫Û£¨–Ë“™÷˜∂صΩ∑˛ŒÒ∂ÀªÒ»°◊Ó–¬µƒ ˝æ›£®Õ∆¿≠Ω·∫œ£©°£
3.2 √¸√˚∑˛ŒÒ(Naming Service)
√¸√˚∑˛ŒÒ“≤ «∑÷≤º ΩœµÕ≥÷–±»Ωœ≥£º˚µƒ“ª¿‡≥°æ∞°£‘⁄∑÷≤º ΩœµÕ≥÷–£¨Õ®π˝ π”√√¸√˚∑˛ŒÒ£¨øÕªß∂À”¶”√ƒ‹πª∏˘æ›÷∏∂®√˚◊÷¿¥ªÒ»°◊ ‘¥ªÚ∑˛ŒÒµƒµÿ÷∑£¨Ã·π©’flµ»–≈œ¢°£±ª√¸√˚µƒ µÃÂÕ®≥£ø…“‘ «ºØ»∫÷–µƒª˙∆˜£¨Ã·π©µƒ∑˛ŒÒ£¨‘∂≥Ã∂‘œÛµ»µ»°™°™’‚–©Œ“√«∂ºø…“‘Õ≥≥∆À˚√«Œ™√˚◊÷£®Name£©°£
∆‰÷–ΩœŒ™≥£º˚µƒæÕ «“ª–©∑÷≤º Ω∑˛ŒÒøÚº‹£®»ÁRPC°¢RMI£©÷–µƒ∑˛ŒÒµÿ÷∑¡–±Ì°£Õ®π˝‘⁄ZooKeepr¿Ô¥¥Ω®À≥–ÚΩ⁄µ„£¨ƒ‹πª∫‹»›“◊¥¥Ω®“ª∏ˆ»´æ÷Œ®“ªµƒ¬∑æ∂£¨’‚∏ˆ¬∑æ∂æÕø…“‘◊˜Œ™“ª∏ˆ√˚◊÷°£
ZooKeeper µƒ√¸√˚∑˛ŒÒº¥…˙≥…»´æ÷Œ®“ªµƒID°£
3.3 ∑÷≤º Ω–≠µ˜/Õ®÷™
ZooKeeper ÷–Ãÿ”– Watcher ◊¢≤·”ΓÏ≤ΩÕ®÷™ª˙÷∆£¨ƒ‹πª∫‹∫√µƒ µœ÷∑÷≤º Ωª∑æ≥œ¬≤ªÕ¨ª˙∆˜£¨…ı÷¡≤ªÕ¨œµÕ≥÷ƺ‰µƒÕ®÷™”Ζ≠µ˜£¨¥”∂¯ µœ÷∂‘ ˝æ›±‰∏¸µƒ µ ±¥¶¿Ì°£ π”√∑Ω∑®Õ®≥£ «≤ªÕ¨µƒøÕªß∂À∂º∂‘ZK…œÕ¨“ª∏ˆ ZNode Ω¯––◊¢≤·£¨º‡Ã˝ ZNode µƒ±‰ªØ£®∞¸¿®ZNode±æ…̃⁄»›º∞◊”Ω⁄µ„µƒ£©£¨»Áπ˚ ZNode ∑¢…˙¡À±‰ªØ£¨ƒ«√¥À˘”–∂©‘ƒµƒøÕªß∂À∂ºƒ‹πªΩ” ’µΩœ‡”¶µƒWatcherÕ®÷™£¨≤¢◊ˆ≥ˆœ‡”¶µƒ¥¶¿Ì°£
ZKµƒ∑÷≤º Ω–≠µ˜/Õ®÷™£¨ «“ª÷÷Õ®”√µƒ∑÷≤º ΩœµÕ≥ª˙∆˜º‰µƒÕ®–≈∑Ω Ω°£
3.3.1 –ƒÃ¯ºÏ≤‚
ª˙∆˜º‰µƒ–ƒÃ¯ºÏ≤‚ª˙÷∆ «÷∏‘⁄∑÷≤º Ωª∑æ≥÷–£¨≤ªÕ¨ª˙∆˜£®ªÚΩ¯≥ã©÷ƺ‰–Ë“™ºÏ≤‚µΩ±À¥À «∑Ò‘⁄’˝≥£‘À––£¨¿˝»ÁAª˙∆˜–Ë“™÷™µ¿Bª˙∆˜ «∑Ò’˝≥£‘À––°£‘⁄¥´Õ≥µƒø™∑¢÷–£¨Œ“√«Õ®≥£ «Õ®π˝÷˜ª˙÷±Ω” «∑Òø…“‘œ‡ª•PINGÕ®¿¥≈–∂œ£¨∏¸∏¥‘”“ªµ„µƒª∞£¨‘Úª·Õ®π˝‘⁄ª˙∆˜÷ƺ‰Ω®¡¢≥§¡¨Ω”£¨Õ®π˝TCP¡¨Ω”πÔ–µƒ–ƒÃ¯ºÏ≤‚ª˙÷∆¿¥ µœ÷…œ≤„ª˙∆˜µƒ–ƒÃ¯ºÏ≤‚£¨’‚–©∂º «∑«≥£≥£º˚µƒ–ƒÃ¯ºÏ≤‚∑Ω∑®°£
œ¬√Ê¿¥ø¥ø¥»Á∫Œ π”√ZK¿¥ µœ÷∑÷≤º Ωª˙∆˜£®Ω¯≥㩺‰µƒ–ƒÃ¯ºÏ≤‚°£
ª˘”⁄ZKµƒ¡Ÿ ±Ω⁄µ„µƒÃÿ–‘£¨ø…“‘»√≤ªÕ¨µƒΩ¯≥Ã∂º‘⁄ZKµƒ“ª∏ˆ÷∏∂®Ω⁄µ„œ¬¥¥Ω®¡Ÿ ±◊”Ω⁄µ„£¨≤ªÕ¨µƒΩ¯≥Ã÷±Ω”ø…“‘∏˘æ›’‚∏ˆ¡Ÿ ±◊”Ω⁄µ„¿¥≈–∂œ∂‘”¶µƒΩ¯≥à «∑ҥʪӰ£Õ®π˝’‚÷÷∑Ω Ω£¨ºÏ≤‚∫Õ±ªºÏ≤‚œµÕ≥÷±Ω”≤¢≤ª–Ë“™÷±Ω”œ‡πÿ¡™£¨∂¯ «Õ®π˝ZK…œµƒƒ≥∏ˆΩ⁄µ„Ω¯––πÿ¡™£¨¥Û¥Ûºı…Ÿ¡ÀœµÕ≥ÒÓ∫œ°£
3.3.2 π§◊˜Ω¯∂»ª„±®
‘⁄“ª∏ˆ≥£º˚µƒ»ŒŒÒ∑÷∑¢œµÕ≥÷–£¨Õ®≥£»ŒŒÒ±ª∑÷∑¢µΩ≤ªÕ¨µƒª˙∆˜…œ÷¥––∫Û£¨–Ë“™ µ ±µÿΩ´◊‘º∫µƒ»ŒŒÒ÷¥––Ω¯∂»ª„±®∏¯∑÷∑¢œµÕ≥°£’‚∏ˆ ±∫ÚæÕø…“‘Õ®π˝ZK¿¥ µœ÷°£‘⁄ZK…œ—°‘Ò“ª∏ˆΩ⁄µ„£¨√ø∏ˆ»ŒŒÒøÕªß∂À∂º‘⁄’‚∏ˆΩ⁄µ„œ¬√Ê¥¥Ω®¡Ÿ ±◊”Ω⁄µ„£¨’‚—˘±„ø…“‘ µœ÷¡Ω∏ˆπ¶ƒ‹£∫
Õ®π˝≈–∂œ¡Ÿ ±Ω⁄µ„ «∑ҥʑ⁄¿¥»∑∂®»ŒŒÒª˙∆˜ «∑ҥʪӰ£
∏˜∏ˆ»ŒŒÒª˙∆˜ª· µ ±µÿΩ´◊‘º∫µƒ»ŒŒÒ÷¥––Ω¯∂»–¥µΩ’‚∏ˆ¡Ÿ ±Ω⁄µ„…œ»•£¨“‘±„÷––ƒœµÕ≥ƒ‹πª µ ±µÿªÒ»°µΩ»ŒŒÒµƒ÷¥––Ω¯∂»°£
3.4 Master—°æŸ
Master —°æŸø…“‘Àµ « ZooKeeper ◊Óµ‰–Õµƒ”¶”√≥°æ∞¡À°£±»»Á HDFS ÷– Active NameNode µƒ—°æŸ°¢YARN ÷– Active ResourceManager µƒ—°æŸ∫Õ HBase ÷– Active HMaster µƒ—°æŸµ»°£
’Î∂‘ Master —°æŸµƒ–Ë«Û£¨Õ®≥£«Èøˆœ¬£¨Œ“√«ø…“‘—°‘Ò≥£º˚µƒπÿœµ–Õ ˝æ›ø‚÷–µƒ÷˜º¸Ãÿ–‘¿¥ µœ÷£∫œ£Õ˚≥…Œ™ Master µƒª˙∆˜∂ºœÚ ˝æ›ø‚÷–≤»ΓªÃıœ‡Õ¨÷˜º¸IDµƒº«¬º£¨ ˝æ›ø‚ª·∞ÔŒ“√«Ω¯––÷˜º¸≥ÂÕªºÏ≤È£¨“≤æÕ «Àµ£¨÷ª”–“ªÃ®ª˙∆˜ƒ‹≤»Î≥…π¶°™°™ƒ«√¥£¨Œ“√«æÕ»œŒ™œÚ ˝æ›ø‚÷–≥…π¶≤»Π˝æ›µƒøÕªß∂Àª˙∆˜≥…Œ™Master°£
“¿øøπÿœµ–Õ ˝æ›ø‚µƒ÷˜º¸Ãÿ–‘»∑ µƒ‹πª∫‹∫√µÿ±£÷§‘⁄ºØ»∫÷–—°æŸ≥ˆŒ®“ªµƒ“ª∏ˆMaster°£
µ´ «£¨»Áπ˚µ±«∞—°æŸ≥ˆµƒ Master π“¡À£¨ƒ«√¥∏√»Á∫Œ¥¶¿Ì£øÀ≠¿¥∏ÊÀflŒ“ Master π“¡Àƒÿ£øœ‘»ª£¨πÿœµ–Õ ˝æ›ø‚Œfi∑®Õ®÷™Œ“√«’‚∏ˆ ¬º˛°£µ´ «£¨ZooKeeper ø…“‘◊ˆµΩ£°
¿˚”√ ZooKeepr µƒ«ø“ª÷¬–‘£¨ƒ‹πª∫‹∫√µÿ±£÷§‘⁄∑÷≤º Ω∏fl≤¢∑¢«Èøˆœ¬Ω⁄µ„µƒ¥¥Ω®“ª∂®ƒ‹πª±£÷§»´æ÷Œ®“ª–‘£¨º¥ ZooKeeper Ω´ª·±£÷§øÕªß∂ÀŒfi∑®¥¥Ω®“ª∏ˆ“—æ≠¥Ê‘⁄µƒ ZNode°£
“≤æÕ «Àµ£¨»Áπ˚Õ¨ ±”–∂‡∏ˆøÕªß∂À«Î«Û¥¥Ω®Õ¨“ª∏ˆ¡Ÿ ±Ω⁄µ„£¨ƒ«√¥◊Ó÷’“ª∂®÷ª”–“ª∏ˆøÕªß∂À«Î«Ûƒ‹πª¥¥Ω®≥…π¶°£¿˚”√’‚∏ˆÃÿ–‘£¨æÕƒ‹∫‹»›“◊µÿ‘⁄∑÷≤º Ωª∑æ≥÷–Ω¯–– Master —°æŸ¡À°£
≥…𶥥ٮ∏√Ω⁄µ„µƒøÕªß∂ÀÀ˘‘⁄µƒª˙∆˜æÕ≥…Œ™¡À Master°£Õ¨ ±£¨∆‰À˚√ª”–≥…𶥥ٮ∏√Ω⁄µ„µƒøÕªß∂À£¨∂ºª·‘⁄∏√Ω⁄µ„…œ◊¢≤·“ª∏ˆ◊”Ω⁄µ„±‰∏¸µƒ Watcher£¨”√”⁄º‡øÿµ±«∞ Master ª˙∆˜ «∑ҥʪӣ¨“ªµ©∑¢œ÷µ±«∞µƒMasterπ“¡À£¨ƒ«√¥∆‰À˚øÕªß∂ÀΩ´ª·÷ÿ–¬Ω¯–– Master —°æŸ°£
’‚—˘æÕ µœ÷¡À Master µƒ∂Ø藰柰£
3.5 ∑÷≤º ΩÀ¯
∑÷≤º ΩÀ¯ «øÿ÷∆∑÷≤º ΩœµÕ≥÷ƺ‰Õ¨≤Ω∑√Œ π≤œÌ◊ ‘¥µƒ“ª÷÷∑Ω Ω°£
∑÷≤º ΩÀ¯”÷∑÷Œ™≈≈À˚À¯∫Õπ≤œÌÀ¯¡Ω÷÷°£
3.5.1 ≈≈À˚À¯
≈≈À˚À¯£®Exclusive Locks£¨ºÚ≥∆XÀ¯£©£¨”÷≥∆Œ™–¥À¯ªÚ∂¿’ºÀ¯°£
»Áπ˚ ¬ŒÒT1∂‘ ˝æ›∂‘œÛO1º”…œ¡À≈≈À˚À¯£¨ƒ«√¥‘⁄’˚∏ˆº”À¯∆⁄º‰£¨÷ª‘ –Ì ¬ŒÒT1∂‘O1Ω¯––∂¡»°∫Õ∏¸–¬≤Ÿ◊˜£¨∆‰À˚»Œ∫Œ ¬ŒÒ∂º≤ªƒ‹‘⁄∂‘’‚∏ˆ ˝æ›∂‘œÛΩ¯––»Œ∫Œ¿‡–Õµƒ≤Ÿ◊˜£®≤ªƒ‹‘Ÿ∂‘∏√∂‘œÛº”À¯£©£¨÷±µΩT1 Õ∑≈¡À≈≈À˚À¯°£
ø…“‘ø¥≥ˆ£¨≈≈À˚À¯µƒ∫À–ƒ «»Á∫Œ±£÷§µ±«∞÷ª”–“ª∏ˆ ¬ŒÒªÒµ√À¯£¨≤¢«“À¯±ª Õ∑≈∫Û£¨À˘”–’˝‘⁄µ»¥˝ªÒ»°À¯µƒ ¬ŒÒ∂ºƒ‹πª±ªÕ®÷™µΩ°£
»Á∫Œ¿˚”√ ZooKeeper µœ÷≈≈À˚À¯£ø
∂®“ÂÀ¯
ZooKeeper …œµƒ“ª∏ˆ ZNode ø…“‘±Ì 擪∏ˆÀ¯°£¿˝»Á /exclusive_lock/lockΩ⁄µ„æÕø…“‘±ª∂®“ÂŒ™“ª∏ˆÀ¯°£
ªÒµ√À¯
»Á…œÀ˘Àµ£¨∞—ZooKeeper…œµƒ“ª∏ˆZNodeø¥◊˜ «“ª∏ˆÀ¯£¨ªÒµ√À¯æÕÕ®π˝¥¥Ω® ZNode µƒ∑Ω Ω¿¥ µœ÷°£À˘”–øÕªß∂À∂º»• /exclusive_lockΩ⁄µ„œ¬¥¥Ω®¡Ÿ ±◊”Ω⁄µ„ /exclusive_lock/lock°£ZooKeeper ª·±£÷§‘⁄À˘”–øÕªß∂À÷–£¨◊Ó÷’÷ª”–“ª∏ˆøÕªß∂Àƒ‹πª¥¥Ω®≥…𶣨ƒ«√¥æÕø…“‘»œŒ™∏√øÕªß∂ÀªÒµ√¡ÀÀ¯°£Õ¨ ±£¨À˘”–√ª”–ªÒ»°µΩÀ¯µƒøÕªß∂ÀæÕ–Ë“™µΩ/exclusive_lockΩ⁄µ„…œ◊¢≤·“ª∏ˆ◊”Ω⁄µ„±‰∏¸µƒWatcherº‡Ã˝£¨“‘±„ µ ±º‡Ã˝µΩlockΩ⁄µ„µƒ±‰∏¸«Èøˆ°£
Õ∑≈À¯
“ÚŒ™ /exclusive_lock/lock «“ª∏ˆ¡Ÿ ±Ω⁄µ„£¨“Ú¥À‘⁄“‘œ¬¡Ω÷÷«Èøˆœ¬£¨∂º”–ø…ƒ‹ Õ∑≈À¯°£
µ±«∞ªÒµ√À¯µƒøÕªß∂Àª˙∆˜∑¢…˙Â¥ª˙ªÚ÷ÿ∆Ù£¨ƒ«√¥∏√¡Ÿ ±Ω⁄µ„æÕª·±ª…æ≥˝£¨ Õ∑≈À¯°£
’˝≥£÷¥––ÕÍ“µŒÒ¬flº≠∫Û£¨øÕªß∂ÀæÕª·÷˜∂ØΩ´◊‘º∫¥¥Ω®µƒ¡Ÿ ±Ω⁄µ„…æ≥˝£¨ Õ∑≈À¯°£
Œfi¬€‘⁄ ≤√¥«Èøˆœ¬“∆≥˝¡ÀlockΩ⁄µ„£¨ZooKeeper ∂ºª·Õ®÷™À˘”–‘⁄ /exclusive_lock Ω⁄µ„…œ◊¢≤·¡ÀΩ⁄µ„±‰∏¸ Watcher º‡Ã˝µƒøÕªß∂À°£’‚–©øÕªß∂À‘⁄Ω” ’µΩÕ®÷™∫Û£¨‘Ÿ¥Œ÷ÿ–¬∑¢∆∑÷≤º ΩÀ¯ªÒ»°£¨º¥÷ÿ∏¥°∫ªÒ»°À¯°ªπ˝≥ð£
3.5.2 π≤œÌÀ¯
π≤œÌÀ¯£®Shared Locks£¨ºÚ≥∆SÀ¯£©£¨”÷≥∆Œ™∂¡À¯°£»Áπ˚ ¬ŒÒT1∂‘ ˝æ›∂‘œÛO1º”…œ¡Àπ≤œÌÀ¯£¨ƒ«√¥T1÷ªƒ‹∂‘O1Ω¯––∂¡≤Ÿ◊˜£¨∆‰À˚ ¬ŒÒ“≤ƒ‹Õ¨ ±∂‘O1º”π≤œÌÀ¯£®≤ªƒ‹ «≈≈À˚À¯£©£¨÷±µΩO1…œµƒÀ˘”–π≤œÌÀ¯∂º Õ∑≈∫ÛO1≤≈ƒ‹±ªº”≈≈À˚À¯°£
◊‹Ω·£∫ø…“‘∂‡∏ˆ ¬ŒÒÕ¨ ±ªÒµ√“ª∏ˆ∂‘œÛµƒπ≤œÌÀ¯£®Õ¨ ±∂¡£©£¨”–π≤œÌÀ¯æÕ≤ªƒ‹‘Ÿº”≈≈À˚À¯£®“ÚŒ™≈≈À˚À¯ «–¥À¯£©
4°¢ZooKeeper‘⁄¥Û–Õ∑÷≤º ΩœµÕ≥÷–µƒ”¶”√
«∞√Ê“—æ≠ΩÈ…‹¡À ZooKeeper µƒµ‰–Õ”¶”√≥°æ∞°£±æΩ⁄Ω´“‘≥£º˚µƒ¥Û ˝æ›≤˙∆∑ Hadoop ∫Õ HBase Œ™¿˝¿¥ΩÈ…‹ ZooKeeper ‘⁄∆‰÷–µƒ”¶”√£¨∞Ô÷˙¥Ûº“∏¸∫√µÿ¿ÌΩ‚ ZooKeeper µƒ∑÷≤º Ω”¶”√≥°æ∞°£
4.1 ZooKeeper‘⁄Hadoop÷–µƒ”¶”√
‘⁄ Hadoop ÷–£¨ZooKeeper ÷˜“™”√”⁄ µœ÷ HA(Hive Availability£©£¨∞¸¿® HDFSµƒ NamaNode ∫Õ YARN µƒ ResourceManager µƒ HA°£Õ¨ ±£¨‘⁄ YARN ÷–£¨ ZooKeepr ªπ”√¿¥¥Ê¥¢”¶”√µƒ‘À––◊¥Ã¨°£
HDFS µƒ NamaNode ∫Õ YARN µƒ ResourceManager ¿˚”√ ZooKeepr µœ÷ HA µƒ‘≠¿Ì «“ª—˘µƒ£¨À˘“‘±æΩ⁄“‘YARNŒ™¿˝¿¥ΩÈ…‹°£
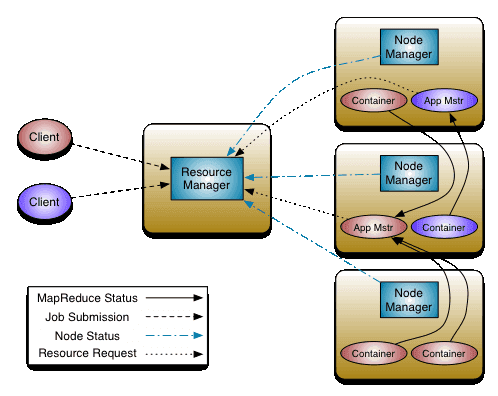
¥”…œÕºø…“‘ø¥≥ˆ£¨YARN÷˜“™”…ResourceManager£®RM£©°¢NodeManager£®NM£©°¢ApplicationMaster£®AM£©∫ÕContainerÀƒ≤ø∑÷◊È≥…°£∆‰÷–◊Ó∫À–ƒµƒæÕ «ResourceManager°£
ResourceManager ∏∫‘ºØ»∫÷–À˘”–◊ ‘¥µƒÕ≥“ªπ‹¿Ì∫Õ∑÷≈‰£¨Õ¨ ±Ω” ’¿¥◊‘∏˜∏ˆΩ⁄µ„£®NodeManager£©µƒ◊ ‘¥ª„±®–≈œ¢£¨≤¢∞—’‚–©–≈œ¢∞¥’’“ª∂®µƒ≤fl¬‘∑÷≈‰∏¯∏˜∏ˆ”¶”√≥Öڣ®Application Manager£©£¨∆‰ƒ⁄≤øŒ¨ª§¡À∏˜∏ˆ”¶”√≥ÖڵƒApplicationMaster–≈œ¢°¢NodeManager–≈œ¢“‘º∞◊ ‘¥ π”√–≈œ¢µ»°£
Œ™¡À µœ÷HA£¨±ÿ–Δ–∂‡∏ˆResourceManager≤¢¥Ê£®“ª∞„æÕ¡Ω∏ˆ£©£¨≤¢«“÷ª”–“ª∏ˆResourceManager¥¶”⁄Active◊¥Ã¨£¨∆‰À˚µƒ‘Ú¥¶”⁄Standby◊¥Ã¨£¨µ±ActiveΩ⁄µ„Œfi∑®’˝≥£π§◊˜£®»Áª˙∆˜Â¥ª˙ªÚ÷ÿ∆Ù£© ±£¨¥¶”⁄StandbyµƒæÕª·Õ®π˝æ∫’˘—°æŸ≤˙…˙–¬µƒActiveΩ⁄µ„°£
4.2 ÷˜±∏«–ªª
œ¬√ÊŒ“√«æÕ¿¥ø¥ø¥YARN «»Á∫Œ µœ÷∂‡∏ˆResourceManager÷ƺ‰µƒ÷˜±∏«–ªªµƒ°£
1. ¥¥Ω®À¯Ω⁄µ„
‘⁄ ZooKeeper …œª·”–“ª∏ˆ/yarn-leader-election/appcluster-yarnµƒÀ¯Ω⁄µ„£¨À˘”–µƒ ResourceManager ‘⁄∆Ù∂صƒ ±∫Ú£¨∂ºª·»•æ∫’˘–¥“ª∏ˆLock◊”Ω⁄µ„£∫/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb£¨∏√Ω⁄µ„ «¡Ÿ ±Ω⁄µ„°£
ZooKeepr ƒ‹πªŒ™Œ“√«±£÷§◊Ó÷’÷ª”–“ª∏ˆResourceManagerƒ‹πª¥¥Ω®≥…π¶°£¥¥Ω®≥…𶵃ƒ«∏ˆ ResourceManager æÕ«–ªªŒ™ Active ◊¥Ã¨£¨√ª”–≥…𶵃ƒ«–© ResourceManager ‘Ú«–ªªŒ™ Standby ◊¥Ã¨°£
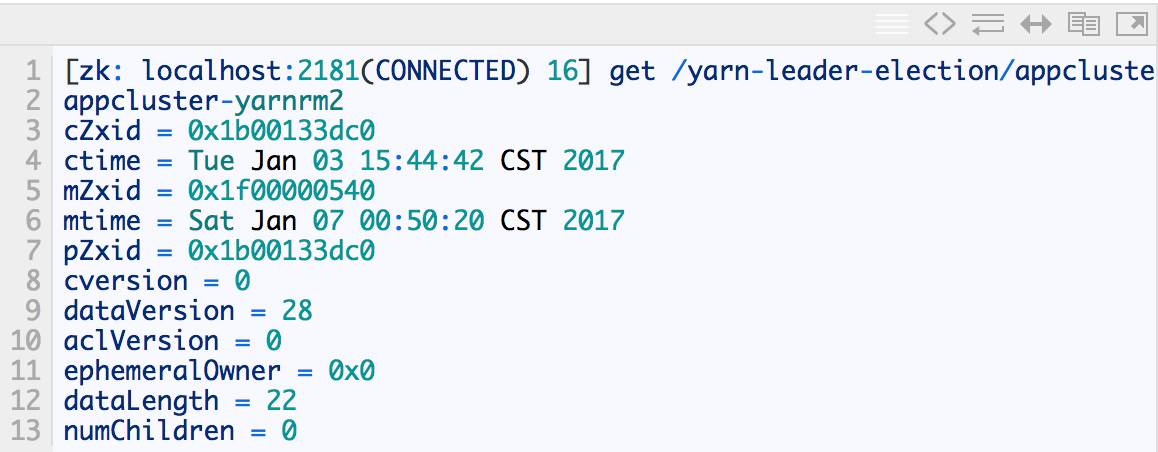
ø…“‘ø¥µΩ¥À ±ºØ»∫÷– ResourceManager2 Œ™ Active°£
◊¢≤· Watcher º‡Ã˝
À˘”– Standby ◊¥Ã¨µƒ ResourceManager ∂ºª·œÚ /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb Ω⁄µ„◊¢≤·“ª∏ˆΩ⁄µ„±‰∏¸µƒWatcherº‡Ã˝£¨¿˚”√¡Ÿ ±Ω⁄µ„µƒÃÿ–‘£¨ƒ‹πªøÏÀŸ∏–÷™µΩActive◊¥Ã¨µƒResourceManagerµƒ‘À––«Èøˆ°£÷˜±∏«–ªª
µ±Active◊¥Ã¨µƒResourceManager≥ˆœ÷÷Ó»ÁÂ¥ª˙ªÚ÷ÿ∆Ùµƒ“Ï≥£«Èøˆ ±£¨∆‰‘⁄ZooKeeper…œ¡¨Ω”µƒøÕªß∂Àª·ª∞æÕª· ߖߣ¨“Ú¥À/yarn-leader-election/appcluster-yarn/ActiveBreadCrumbΩ⁄µ„æÕª·±ª…æ≥˝°£¥À ±∆‰”‡∏˜∏ˆStandby◊¥Ã¨µƒResourceManageræÕ∂ºª·Ω” ’µΩ¿¥◊‘ZooKeeper∑˛ŒÒ∂ÀµƒWatcher ¬º˛Õ®÷™£¨»ª∫Ûª·÷ÿ∏¥Ω¯––≤Ω÷Ë1µƒ≤Ÿ◊˜°£
“‘…œæÕ «¿˚”√ ZooKeeper ¿¥ µœ÷ ResourceManager µƒ÷˜±∏«–ªªµƒπ˝≥㨠µœ÷¡À ResourceManager µƒHA°£
HDFS ÷– NameNode µƒ HA µƒ µœ÷‘≠¿Ì∏˙ YARN ÷– ResourceManager µƒ HA µƒ µœ÷‘≠¿Ìœ‡Õ¨°£∆‰À¯Ω⁄µ„Œ™ /hadoop-ha/mycluster/ActiveBreadCrumb°£
4.3 ResourceManager◊¥Ã¨¥Ê¥¢
‘⁄ ResourceManager ÷–£¨RMStateStore ƒ‹πª¥Ê¥¢“ª–© RM µƒƒ⁄≤ø◊¥Ã¨–≈œ¢£¨∞¸¿® Application “‘º∞À¸√«µƒ Attempts –≈œ¢°¢Delegation Token º∞ Version Information µ»°£–Ë“™◊¢“‚µƒ «£¨RMStateStore ÷–µƒæ¯¥Û∂‡ ˝◊¥Ã¨–≈œ¢∂º «≤ª–Ë“™≥÷æ√ªØ¥Ê¥¢µƒ£¨“ÚŒ™∫‹»›“◊¥”…œœ¬Œƒ–≈œ¢÷–Ω´∆‰÷ÿππ≥ˆ¿¥£¨»Á◊ ‘¥µƒ π”√«Èøˆ°£‘⁄¥Ê¥¢µƒ…˺∆∑Ω∞∏÷–£¨Ã·π©¡À»˝÷÷ø…ƒ‹µƒ µœ÷£¨∑÷±»Áœ¬°£
ª˘”⁄ƒ⁄¥Ê µœ÷£¨“ª∞„ «”√”⁄»’≥£ø™∑¢≤‚ ‘°£
ª˘”⁄Œƒº˛œµÕ≥µƒ µœ÷£¨»ÁHDFS°£
ª˘”⁄ ZooKeeper µœ÷°£
”…”⁄’‚–©◊¥Ã¨–≈œ¢µƒ ˝æ›¡ø∂º≤ª «∫‹¥Û£¨“Ú¥À Hadoop πŸ∑ΩΩ®“Ȫ˘”⁄ ZooKeeper ¿¥ µœ÷◊¥Ã¨–≈œ¢µƒ¥Ê¥¢°£‘⁄ ZooKeepr …œ£¨ResourceManager µƒ◊¥Ã¨–≈œ¢∂º±ª¥Ê¥¢‘⁄ /rmstore ’‚∏ˆ∏˘Ω⁄µ„œ¬√Ê°£

RMAppRoot Ω⁄µ„œ¬¥Ê¥¢µƒ «”Î∏˜∏ˆ Application œ‡πÿµƒ–≈œ¢£¨RMDTSecretManagerRoot ¥Ê¥¢µƒ «”Î∞≤»´œ‡πÿµƒ Token µ»–≈œ¢°£√ø∏ˆ Active ◊¥Ã¨µƒ ResourceManager ‘⁄≥ı ºªØΩ◊∂Œ∂ºª·¥” ZooKeeper …œ∂¡»°µΩ’‚–©◊¥Ã¨–≈œ¢£¨≤¢∏˘æ›’‚–©◊¥Ã¨–≈œ¢ºÃ–¯Ω¯––œ‡”¶µƒ¥¶¿Ì°£
4.4 –°Ω·£∫
ZooKeepr ‘⁄ Hadoop ÷–µƒ”¶”√÷˜“™”–£∫
HDFS ÷– NameNode µƒ HA ∫Õ YARN ÷– ResourceManager µƒ HA°£
¥Ê¥¢ RMStateStore ◊¥Ã¨–≈œ¢
5°¢ZooKeeper‘⁄HBase÷–µƒ”¶”√
HBase ÷˜“™”√ ZooKeeper ¿¥ µœ÷ HMaster —°æŸ”Î÷˜±∏«–ªª°¢œµÕ≥»›¥Ì°¢RootRegion π‹¿Ì°¢Region◊¥Ã¨π‹¿Ì∫Õ∑÷≤º Ω SplitWAL »ŒŒÒπ‹¿Ìµ»°£
5.1 HMaster—°æŸ”Î÷˜±∏«–ªª
HMaster—°æŸ”Î÷˜±∏«–ªªµƒ‘≠¿Ì∫ÕHDFS÷–NameNodeº∞YARN÷–ResourceManagerµƒHA‘≠¿Ìœ‡Õ¨°£
5.2 œµÕ≥»›¥Ì
µ± HBase ∆Ù∂Ø ±£¨√ø∏ˆ RegionServer ∂ºª·µΩ ZooKeeper µƒ/hbase/rsΩ⁄µ„œ¬¥¥Ω®“ª∏ˆ–≈œ¢Ω⁄µ„£®œ¬Œƒ÷–£¨Œ“√«≥∆∏√Ω⁄µ„Œ™°±rs◊¥Ã¨Ω⁄µ„°±£©£¨¿˝»Á/hbase/rs/[Hostname]£¨Õ¨ ±£¨HMaster ª·∂‘’‚∏ˆΩ⁄µ„◊¢≤·º‡Ã˝°£µ±ƒ≥∏ˆ RegionServer π“µÙµƒ ±∫Ú£¨ZooKeeper ª·“ÚŒ™‘⁄“ª∂Œ ±º‰ƒ⁄Œfi∑®Ω” ‹∆‰–ƒÃ¯£®º¥ Session ߖߣ©£¨∂¯…æ≥˝µÙ∏√ RegionServer ∑˛ŒÒ∆˜∂‘”¶µƒ rs ◊¥Ã¨Ω⁄µ„°£
”Î¥ÀÕ¨ ±£¨HMaster ‘Úª·Ω” ’µΩ ZooKeeper µƒ NodeDelete Õ®÷™£¨¥”∂¯∏–÷™µΩƒ≥∏ˆΩ⁄µ„∂œø™£¨≤¢¡¢º¥ø™ º»›¥Ìπ§◊˜°£
HBase Œ™ ≤√¥≤ª÷±Ω”»√ HMaster ¿¥∏∫‘ RegionServer µƒº‡øÿƒÿ£ø»Áπ˚ HMaster ÷±Ω”Õ®π˝–ƒÃ¯ª˙÷∆µ»¿¥π‹¿ÌRegionServerµƒ◊¥Ã¨£¨ÀÊ◊≈ºØ»∫‘Ω¿¥‘Ω¥Û£¨HMaster µƒπ‹¿Ì∏∫µ£ª·‘Ω¿¥‘Ω÷ÿ£¨¡ÌÕ‚À¸◊‘…Ì“≤”–π“µÙµƒø…ƒ‹£¨“Ú¥À ˝æ›ªπ–Ë“™≥÷æ√ªØ°£‘⁄’‚÷÷«Èøˆœ¬£¨ZooKeeper æÕ≥…¡À¿ÌœÎµƒ—°‘Ò°£
5.3 RootRegionπ‹¿Ì
∂‘”¶ HBase ºØ»∫¿¥Àµ£¨ ˝æ›¥Ê¥¢µƒŒª÷√–≈œ¢ «º«¬º‘⁄‘™ ˝æ› region£¨“≤æÕ « RootRegion …œµƒ°£√ø¥ŒøÕªß∂À∑¢∆–¬µƒ«Î«Û£¨–Ë“™÷™µ¿ ˝æ›µƒŒª÷√£¨æÕª·»•≤È—Ø RootRegion£¨∂¯ RootRegion ◊‘…ÌŒª÷√‘Ú «º«¬º‘⁄ ZooKeeper …œµƒ£®ƒ¨»œ«Èøˆœ¬£¨ «º«¬º‘⁄ ZooKeeper µƒ/hbase/meta-region-serverΩ⁄µ„÷–£©°£
µ± RootRegion ∑¢…˙±‰ªØ£¨±»»Á Region µƒ ÷π§“∆∂Ø°¢÷ÿ–¬∏∫‘ÿæ˘∫‚ªÚ RootRegion À˘‘⁄∑˛ŒÒ∆˜∑¢…˙¡Àπ ’œµ» «£¨æÕƒ‹πªÕ®π˝ ZooKeeper ¿¥∏–÷™µΩ’‚“ª±‰ªØ≤¢◊ˆ≥ˆ“ªœµ¡–œ‡”¶µƒ»›‘÷¥Î ©£¨¥”∂¯±£÷§øÕªß∂À◊‹ «ƒ‹πªƒ√µΩ’˝»∑µƒ RootRegion –≈œ¢°£
5.4 Regionπ‹¿Ì
HBase ¿Ôµƒ Region ª·æ≠≥£∑¢…˙±‰∏¸£¨’‚–©±‰∏¸µƒ‘≠“Ú¿¥◊‘”⁄œµÕ≥π ’œ°¢∏∫‘ÿæ˘∫‚°¢≈‰÷√–fi∏ƒ°¢Region ∑÷¡—”Î∫œ≤¢µ»°£“ªµ© Region ∑¢…˙“∆∂Ø£¨À¸æÕª·æ≠¿˙œ¬œfl£®offline£©∫Õ÷ÿ–¬…œœfl£®online£©µƒπ˝≥ð£
‘⁄œ¬œfl∆⁄º‰ ˝æ› «≤ªƒ‹±ª∑√Œ µƒ£¨≤¢«“ Region µƒ’‚∏ˆ◊¥Ã¨±‰ªØ±ÿ–λ√»´æ÷÷™œ˛£¨∑Ò‘Úø…ƒ‹ª·≥ˆœ÷ ¬ŒÒ–‘µƒ“Ï≥£°£
∂‘”⁄¥Ûµƒ HBase ºØ»∫¿¥Àµ£¨Region µƒ ˝¡øø…ƒ‹ª·∂‡¥Ô ÆÕÚº∂±£¨…ı÷¡∏¸∂‡£¨’‚—˘πʃ£µƒ Region ◊¥Ã¨π‹¿ÌΩª∏¯ ZooKeeper ¿¥◊ˆ“≤ «“ª∏ˆ∫‹∫√µƒ—°‘Ò°£
5.5 ∑÷≤º ΩSplitWAL»ŒŒÒπ‹¿Ì
µ±ƒ≥î RegionServer ∑˛ŒÒ∆˜π“µÙ ±£¨”…”⁄◊‹”–“ª≤ø∑÷–¬–¥»Îµƒ ˝æ›ªπ√ª”–≥÷æ√ªØµΩ HFile ÷–£¨“Ú¥À‘⁄«®“∆∏√ RegionServer µƒ∑˛ŒÒ ±£¨“ª∏ˆ÷ÿ“™µƒπ§◊˜æÕ «¥” WAL ÷–ª÷∏¥’‚≤ø∑÷ªπ‘⁄ƒ⁄¥Ê÷–µƒ ˝æ›£¨∂¯’‚≤ø∑÷π§◊˜◊Óπÿº¸µƒ“ª≤ΩæÕ « SplitWAL£¨º¥ HMaster –Ë“™±È¿˙∏√ RegionServer ∑˛ŒÒ∆˜µƒ WAL£¨≤¢∞¥ Region «–∑÷≥…–°øÈ“∆∂ØµΩ–¬µƒµÿ÷∑œ¬£¨≤¢Ω¯––»’÷浃ªÿ∑≈£®replay£©°£
”…”⁄µ•∏ˆ RegionServer µƒ»’÷æ¡øœ‡∂‘≈”¥Û£®ø…ƒ‹”–…œ«ß∏ˆ Region£¨…œGBµƒ»’÷棩£¨∂¯”√ªß”÷Õ˘Õ˘œ£Õ˚œµÕ≥ƒ‹πªøÏÀŸÕÍ≥…»’÷浃ª÷∏¥π§◊˜°£“Ú¥À“ª∏ˆø…––µƒ∑Ω∞∏ «Ω´’‚∏ˆ¥¶¿ÌWALµƒ»ŒŒÒ∑÷∏¯∂‡Ã® RegionServer ∑˛ŒÒ∆˜¿¥π≤Õ¨¥¶¿Ì£¨∂¯’‚æÕ”÷–Ë“™“ª∏ˆ≥÷æ√ªØ◊Ⱥ˛¿¥∏®÷˙ HMaster ÕÍ≥…»ŒŒÒµƒ∑÷≈‰°£
µ±«∞µƒ◊ˆ∑® «£¨ HMaster ª·‘⁄ ZooKeeper …œ¥¥Ω®“ª∏ˆ SplitWAL Ω⁄µ„£®ƒ¨»œ«Èøˆœ¬£¨ «/hbase/SplitWALΩ⁄µ„£©£¨Ω´°∞ƒƒ∏ˆ RegionServer ¥¶¿Ìƒƒ∏ˆ Region°±’‚—˘µƒ–≈œ¢“‘¡–±Ìµƒ–Œ Ω¥Ê∑≈µΩ∏√Ω⁄µ„…œ£¨»ª∫Û”…∏˜∏ˆ RegionServer ∑˛ŒÒ∆˜◊‘––µΩ∏√Ω⁄µ„…œ»•¡Ï»°»ŒŒÒ≤¢‘⁄»ŒŒÒ÷¥––≥…π¶ªÚ ß∞‹∫Û‘Ÿ∏¸–¬∏√Ω⁄µ„µƒ–≈œ¢£¨“‘Õ®÷™ HMaster ºÃ–¯Ω¯––∫Û√ʵƒ≤Ω÷Ë°£ ZooKeeper ‘⁄’‚¿Ôµ£∏∫∆¡À∑÷≤º ΩºØ»∫÷–œ‡ª•Õ®÷™∫Õ–≈œ¢≥÷æ√ªØµƒΩ«…´°£
5.6 –°Ω·£∫
“‘…œæÕ «“ª–© HBase ÷–“¿¿µ ZooKeeper ÕÍ≥…∑÷≤º Ω–≠µ˜π¶ƒ‹µƒµ‰–Õ≥°æ∞°£µ´ ¬ µ…œ£¨HBase ∂‘ ZooKeeper µƒ“¿¿µªπ≤ª÷π’‚–©£¨±»»Á HMaster ªπ“¿¿µ ZooKeeper ¿¥ÕÍ≥… Table µƒ enable/disable ◊¥Ã¨º«¬º£¨“‘º∞ HBase ÷–º∏∫ıÀ˘”–µƒ‘™ ˝æ›¥Ê¥¢∂º «∑≈‘⁄ ZooKeeper …œµƒ°£
”…”⁄ ZooKeeper ≥ˆ…´µƒ∑÷≤º Ω–≠µ˜ƒ‹¡¶º∞¡º∫√µƒÕ®÷™ª˙÷∆£¨HBase‘⁄∏˜∞ʱ浃—›Ω¯π˝≥Ã÷–‘Ω¿¥‘Ω∂‡µÿ‘ˆº”¡À ZooKeeper µƒ”¶”√≥°æ∞£¨¥”«˜ ∆…œ¿¥ø¥¡Ω’flµƒΩªºØ‘Ω¿¥‘Ω∂‡°£HBase ÷–À˘”–∂‘ ZooKeeper µƒ≤Ÿ◊˜∂º∑‚◊∞‘⁄¡À org.apache.hadoop.hbase.zookeeper ’‚∏ˆ∞¸÷–£¨∏––À»§µƒÕ¨—ßø…“‘◊‘––—–æø°£